![]()
Latest [Jan 03, 2022] Professional-Machine-Learning-Engineer Exam Questions – Valid Professional-Machine-Learning-Engineer Dumps Pdf
Professional-Machine-Learning-Engineer Practice Test Questions Answers Updated 72 Questions
Understanding functional and technical aspects of Professional Machine Learning Engineer - Google ML Solution Architecture
The following will be discussed in Google Professional-Machine-Learning-Engineer dumps:
- Automation
- Choose appropriate Google Cloud software components
- Choose appropriate Google Cloud hardware components
- Serving
- Automation of data preparation and model training/deployment
- Privacy implications of data usage
- Selection of quotas and compute/accelerators with components
- SDLC best practices
- Monitoring
- Building secure ML systems
- Logging/management
- Design reliable, scalable, highly available ML solution
- Optimizing data use and storage
- Feature engineering
- Design architecture that complies with regulatory and security concerns
- Data connections
- Identifying potential regulatory issues
- Exploration/analysis
- A variety of component types - data collection; data management
Professional Machine Learning Engineer - Google Certification Path
The associate level certification is focused on the fundamental skills of deploying, monitoring, and maintaining projects on Google Cloud. This certification is a good starting point for those new to cloud and can be used as a path to professional level certifications.
Professional certifications span key technical job functions and assess advanced skills in design, implementation, and management. These certifications are recommended for individuals with industry experience and familiarity with Google Cloud products and solutions.
NEW QUESTION 41
A Machine Learning Specialist at a company sensitive to security is preparing a dataset for model training. The dataset is stored in Amazon S3 and contains Personally Identifiable Information (PII).
The dataset:
* Must be accessible from a VPC only.
* Must not traverse the public internet.
How can these requirements be satisfied?
- A. Create a VPC endpoint and use Network Access Control Lists (NACLs) to allow traffic between only the given VPC endpoint and an Amazon EC2 instance.
- B. Create a VPC endpoint and apply a bucket access policy that restricts access to the given VPC endpoint and the VPC.
- C. Create a VPC endpoint and apply a bucket access policy that allows access from the given VPC endpoint and an Amazon EC2 instance.
- D. Create a VPC endpoint and use security groups to restrict access to the given VPC endpoint and an Amazon EC2 instance
Answer: B
NEW QUESTION 42
A Data Scientist received a set of insurance records, each consisting of a record ID, the final outcome among
200 categories, and the date of the final outcome. Some partial information on claim contents is also provided, but only for a few of the 200 categories. For each outcome category, there are hundreds of records distributed over the past 3 years. The Data Scientist wants to predict how many claims to expect in each category from month to month, a few months in advance.
What type of machine learning model should be used?
- A. Classification with supervised learning of the categories for which partial information on claim contents is provided, and forecasting using claim IDs and timestamps for all other categories.
- B. Classification month-to-month using supervised learning of the 200 categories based on claim contents.
- C. Reinforcement learning using claim IDs and timestamps where the agent will identify how many claims in each category to expect from month to month.
- D. Forecasting using claim IDs and timestamps to identify how many claims in each category to expect from month to month.
Answer: A
Explanation:
Explanation
NEW QUESTION 43
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this:
A)
B)
C)
D)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer: C
NEW QUESTION 44
A Machine Learning Specialist is developing a daily ETL workflow containing multiple ETL jobs. The workflow consists of the following processes:
* Start the workflow as soon as data is uploaded to Amazon S3.
* When all the datasets are available in Amazon S3, start an ETL job to join the uploaded datasets with multiple terabyte-sized datasets already stored in Amazon S3.
* Store the results of joining datasets in Amazon S3.
* If one of the jobs fails, send a notification to the Administrator.
Which configuration will meet these requirements?
- A. Use AWS Lambda to trigger an AWS Step Functions workflow to wait for dataset uploads to complete in Amazon S3. Use AWS Glue to join the datasets. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
- B. Use AWS Lambda to chain other Lambda functions to read and join the datasets in Amazon S3 as soon as the data is uploaded to Amazon S3. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
- C. Develop the ETL workflow using AWS Lambda to start an Amazon SageMaker notebook instance. Use a lifecycle configuration script to join the datasets and persist the results in Amazon S3. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
- D. Develop the ETL workflow using AWS Batch to trigger the start of ETL jobs when data is uploaded to Amazon S3. Use AWS Glue to join the datasets in Amazon S3. Use an Amazon CloudWatch alarm to send an SNS notification to the Administrator in the case of a failure.
Answer: A
Explanation:
Explanation/Reference: https://aws.amazon.com/step-functions/use-cases/
NEW QUESTION 45
A gaming company has launched an online game where people can start playing for free, but they need to pay if they choose to use certain features. The company needs to build an automated system to predict whether or not a new user will become a paid user within 1 year. The company has gathered a labeled dataset from 1 million users.
The training dataset consists of 1,000 positive samples (from users who ended up paying within 1 year) and
999,000 negative samples (from users who did not use any paid features). Each data sample consists of 200 features including user age, device, location, and play patterns.
Using this dataset for training, the Data Science team trained a random forest model that converged with over
99% accuracy on the training set. However, the prediction results on a test dataset were not satisfactory Which of the following approaches should the Data Science team take to mitigate this issue? (Choose two.)
- A. Generate more positive samples by duplicating the positive samples and adding a small amount of noise to the duplicated data.
- B. Change the cost function so that false negatives have a higher impact on the cost value than false positives.
- C. Change the cost function so that false positives have a higher impact on the cost value than false negatives.
- D. Include a copy of the samples in the test dataset in the training dataset.
- E. Add more deep trees to the random forest to enable the model to learn more features.
Answer: A,B
NEW QUESTION 46
Machine Learning Specialist is training a model to identify the make and model of vehicles in images. The Specialist wants to use transfer learning and an existing model trained on images of general objects. The Specialist collated a large custom dataset of pictures containing different vehicle makes and models.
What should the Specialist do to initialize the model to re-train it with the custom data?
- A. Initialize the model with pre-trained weights in all layers including the last fully connected layer.
- B. Initialize the model with random weights in all layers and replace the last fully connected layer.
- C. Initialize the model with random weights in all layers including the last fully connected layer.
- D. Initialize the model with pre-trained weights in all layers and replace the last fully connected layer.
Answer: D
Explanation:
Explanation/Reference:
NEW QUESTION 47
A company ingests machine learning (ML) data from web advertising clicks into an Amazon S3 data lake. Click data is added to an Amazon Kinesis data stream by using the Kinesis Producer Library (KPL). The data is loaded into the S3 data lake from the data stream by using an Amazon Kinesis Data Firehose delivery stream.
As the data volume increases, an ML specialist notices that the rate of data ingested into Amazon S3 is relatively constant. There also is an increasing backlog of data for Kinesis Data Streams and Kinesis Data Firehose to ingest.
Which next step is MOST likely to improve the data ingestion rate into Amazon S3?
- A. Increase the number of shards for the data stream.
- B. Decrease the retention period for the data stream.
- C. Add more consumers using the Kinesis Client Library (KCL).
- D. Increase the number of S3 prefixes for the delivery stream to write to.
Answer: A
Explanation:
Explanation/Reference:
NEW QUESTION 48
You are going to train a DNN regression model with Keras APIs using this code:
How many trainable weights does your model have? (The arithmetic below is correct.)
- A. 500*256+256*128+128*2 = 161024
- B. 501*256+257*128+2 = 161154
- C. 500*256*0 25+256*128*0 25+128*2 = 40448
- D. 501*256+257*128+128*2=161408
Answer: C
NEW QUESTION 49
A Machine Learning Specialist previously trained a logistic regression model using scikit-learn on a local machine, and the Specialist now wants to deploy it to production for inference only.
What steps should be taken to ensure Amazon SageMaker can host a model that was trained locally?
- A. Build the Docker image with the inference code. Configure Docker Hub and upload the image to Amazon ECR.
- B. Serialize the trained model so the format is compressed for deployment. Build the image and upload it to Docker Hub.
- C. Serialize the trained model so the format is compressed for deployment. Tag the Docker image with the registry hostname and upload it to Amazon S3.
- D. Build the Docker image with the inference code. Tag the Docker image with the registry hostname and upload it to Amazon ECR.
Answer: A
NEW QUESTION 50
A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a machine learning specialist will build a binary classifier based on two features: age of account, denoted by x, and transaction month, denoted by y. The class distributions are illustrated in the provided figure. The positive class is portrayed in red, while the negative class is portrayed in black.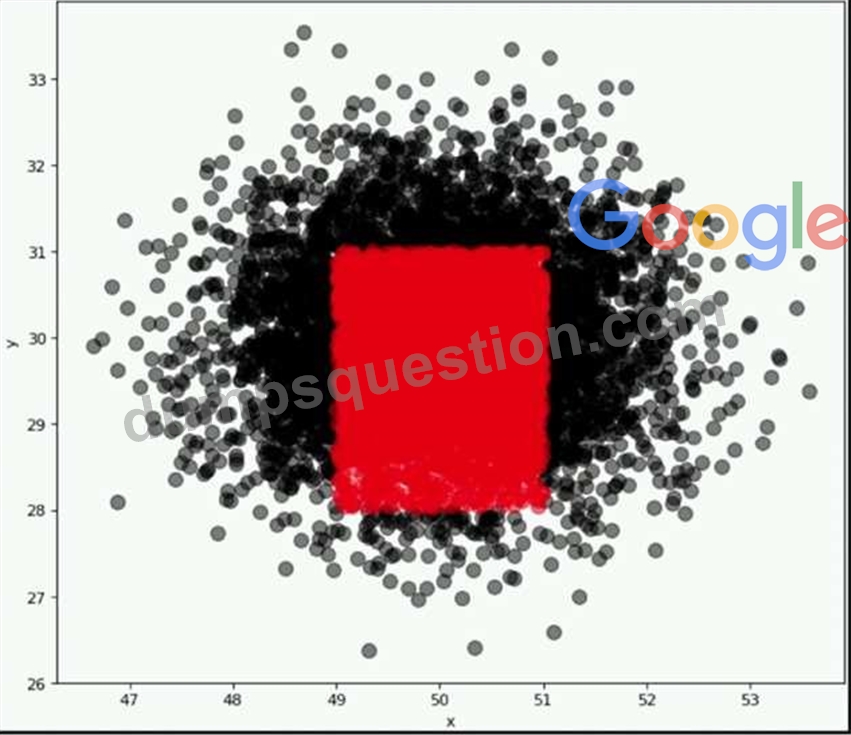
Which model would have the HIGHEST accuracy?
- A. Linear support vector machine (SVM)
- B. Single perceptron with a Tanh activation function
- C. Support vector machine (SVM) with a radial basis function kernel
- D. Decision tree
Answer: C
NEW QUESTION 51
You work on a growing team of more than 50 data scientists who all use AI Platform. You are designing a strategy to organize your jobs, models, and versions in a clean and scalable way. Which strategy should you choose?
- A. Separate each data scientist's work into a different project to ensure that the jobs, models, and versions created by each data scientist are accessible only to that user.
- B. Set up restrictive IAM permissions on the AI Platform notebooks so that only a single user or group can access a given instance.
- C. Use labels to organize resources into descriptive categories. Apply a label to each created resource so that users can filter the results by label when viewing or monitoring the resources.
- D. Set up a BigQuery sink for Cloud Logging logs that is appropriately filtered to capture information about AI Platform resource usage. In BigQuery, create a SQL view that maps users to the resources they are using
Answer: B
NEW QUESTION 52
A Machine Learning Specialist trained a regression model, but the first iteration needs optimizing. The Specialist needs to understand whether the model is more frequently overestimating or underestimating the target.
What option can the Specialist use to determine whether it is overestimating or underestimating the target value?
- A. Confusion matrix
- B. Root Mean Square Error (RMSE)
- C. Residual plots
- D. Area under the curve
Answer: D
NEW QUESTION 53
A Machine Learning Specialist is configuring Amazon SageMaker so multiple Data Scientists can access notebooks, train models, and deploy endpoints. To ensure the best operational performance, the Specialist needs to be able to track how often the Scientists are deploying models, GPU and CPU utilization on the deployed SageMaker endpoints, and all errors that are generated when an endpoint is invoked.
Which services are integrated with Amazon SageMaker to track this information? (Choose two.)
- A. AWS CloudTrail
- B. AWS Config
- C. AWS Health
- D. AWS Trusted Advisor
- E. Amazon CloudWatch
Answer: A,E
Explanation:
Explanation/Reference: https://aws.amazon.com/sagemaker/faqs/
NEW QUESTION 54
A Data Scientist needs to create a serverless ingestion and analytics solution for high-velocity, real-time streaming data.
The ingestion process must buffer and convert incoming records from JSON to a query-optimized, columnar format without data loss. The output datastore must be highly available, and Analysts must be able to run SQL queries against the data and connect to existing business intelligence dashboards.
Which solution should the Data Scientist build to satisfy the requirements?
- A. Use Amazon Kinesis Data Analytics to ingest the streaming data and perform real-time SQL queries to convert the records to Apache Parquet before delivering to Amazon S3. Have the Analysts query the data directly from Amazon S3 using Amazon Athena and connect to BI tools using the Athena Java Database Connectivity (JDBC) connector.
- B. Write each JSON record to a staging location in Amazon S3. Use the S3 Put event to trigger an AWS Lambda function that transforms the data into Apache Parquet or ORC format and writes the data to a processed data location in Amazon S3. Have the Analysts query the data directly from Amazon S3 using Amazon Athena, and connect to BI tools using the Athena Java Database Connectivity (JDBC) connector.
- C. Create a schema in the AWS Glue Data Catalog of the incoming data format. Use an Amazon Kinesis Data Firehose delivery stream to stream the data and transform the data to Apache Parquet or ORC format using the AWS Glue Data Catalog before delivering to Amazon S3. Have the Analysts query the data directly from Amazon S3 using Amazon Athena, and connect to BI tools using the Athena Java Database Connectivity (JDBC) connector.
- D. Write each JSON record to a staging location in Amazon S3. Use the S3 Put event to trigger an AWS Lambda function that transforms the data into Apache Parquet or ORC format and inserts it into an Amazon RDS PostgreSQL database. Have the Analysts query and run dashboards from the RDS database.
Answer: C
Explanation:
Explanation/Reference:
NEW QUESTION 55
A Data Engineer needs to build a model using a dataset containing customer credit card information How can the Data Engineer ensure the data remains encrypted and the credit card information is secure?
- A. Use a custom encryption algorithm to encrypt the data and store the data on an Amazon SageMaker instance in a VPC. Use the SageMaker DeepAR algorithm to randomize the credit card numbers.
- B. Use an IAM policy to encrypt the data on the Amazon S3 bucket and Amazon Kinesis to automatically discard credit card numbers and insert fake credit card numbers.
- C. Use AWS KMS to encrypt the data on Amazon S3 and Amazon SageMaker, and redact the credit card numbers from the customer data with AWS Glue.
- D. Use an Amazon SageMaker launch configuration to encrypt the data once it is copied to the SageMaker instance in a VPC. Use the SageMaker principal component analysis (PCA) algorithm to reduce the length of the credit card numbers.
Answer: D
Explanation:
Explanation/Reference: https://docs.aws.amazon.com/sagemaker/latest/dg/pca.html
NEW QUESTION 56
A Data Science team within a large company uses Amazon SageMaker notebooks to access data stored in Amazon S3 buckets. The IT Security team is concerned that internet-enabled notebook instances create a security vulnerability where malicious code running on the instances could compromise data privacy. The company mandates that all instances stay within a secured VPC with no internet access, and data communication traffic must stay within the AWS network.
How should the Data Science team configure the notebook instance placement to meet these requirements?
- A. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Use IAM policies to grant access to Amazon S3 and Amazon SageMaker.
- B. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Place the Amazon SageMaker endpoint and S3 buckets within the same VPC.
- C. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has S3 VPC endpoints and Amazon SageMaker VPC endpoints attached to it.
- D. Associate the Amazon SageMaker notebook with a private subnet in a VPC. Ensure the VPC has a NAT gateway and an associated security group allowing only outbound connections to Amazon S3 and Amazon SageMaker.
Answer: C
NEW QUESTION 57
A company that promotes healthy sleep patterns by providing cloud-connected devices currently hosts a sleep tracking application on AWS. The application collects device usage information from device users. The company's Data Science team is building a machine learning model to predict if and when a user will stop utilizing the company's devices. Predictions from this model are used by a downstream application that determines the best approach for contacting users.
The Data Science team is building multiple versions of the machine learning model to evaluate each version against the company's business goals. To measure long-term effectiveness, the team wants to run multiple versions of the model in parallel for long periods of time, with the ability to control the portion of inferences served by the models.
Which solution satisfies these requirements with MINIMAL effort?
- A. Build and host multiple models in Amazon SageMaker. Create multiple Amazon SageMaker endpoints, one for each model. Programmatically control invoking different models for inference at the application layer.
- B. Build and host multiple models in Amazon SageMaker. Create an Amazon SageMaker endpoint configuration with multiple production variants. Programmatically control the portion of the inferences served by the multiple models by updating the endpoint configuration.
- C. Build and host multiple models in Amazon SageMaker. Create a single endpoint that accesses multiple models. Use Amazon SageMaker batch transform to control invoking the different models through the single endpoint.
- D. Build and host multiple models in Amazon SageMaker Neo to take into account different types of medical devices. Programmatically control which model is invoked for inference based on the medical device type.
Answer: C
NEW QUESTION 58
A Data Scientist is training a multilayer perception (MLP) on a dataset with multiple classes. The target class of interest is unique compared to the other classes within the dataset, but it does not achieve and acceptable recall metric. The Data Scientist has already tried varying the number and size of the MLP's hidden layers, which has not significantly improved the results. A solution to improve recall must be implemented as quickly as possible.
Which techniques should be used to meet these requirements?
- A. Gather more data using Amazon Mechanical Turk and then retrain
- B. Train an XGBoost model instead of an MLP
- C. Add class weights to the MLP's loss function and then retrain
- D. Train an anomaly detection model instead of an MLP
Answer: B
NEW QUESTION 59
You have deployed multiple versions of an image classification model on Al Platform. You want to monitor the performance of the model versions overtime. How should you perform this comparison?
- A. Compare the mean average precision across the models using the Continuous Evaluation feature
- B. Compare the loss performance for each model on the validation data
- C. Compare the loss performance for each model on a held-out dataset.
- D. Compare the receiver operating characteristic (ROC) curve for each model using the What-lf Tool
Answer: B
NEW QUESTION 60
You are an ML engineer at a bank that has a mobile application. Management has asked you to build an ML-based biometric authentication for the app that verifies a customer's identity based on their fingerprint. Fingerprints are considered highly sensitive personal information and cannot be downloaded and stored into the bank databases. Which learning strategy should you recommend to train and deploy this ML model?
- A. MD5 to encrypt data
- B. Data Loss Prevention API
- C. Federated learning
- D. Differential privacy
Answer: C
NEW QUESTION 61
You are training an LSTM-based model on Al Platform to summarize text using the following job submission script:
You want to ensure that training time is minimized without significantly compromising the accuracy of your model. What should you do?
- A. Modify the 'scale-tier' parameter
- B. Modify the batch size' parameter
- C. Modify the 'learning rate' parameter
- D. Modify the 'epochs' parameter
Answer: D
NEW QUESTION 62
......
Understanding functional and technical aspects of Professional Machine Learning Engineer - Google ML Pipeline Automation & Orchestration
The following will be discussed in Google Professional-Machine-Learning-Engineer dumps:
Design pipeline. Considerations include:
- Implement training pipeline
- Hooking into model and dataset versioning
- Hybrid or multi-cloud strategies
- A/B and canary testing
- Orchestration framework
- Hooking models into existing CI/CD deployment system
- Tuning compute performance
- Model binary options
- Google Cloud serving options
- Use CI/CD to test and deploy models
- Implement serving pipeline
- Setup of trigger and pipeline schedule
- Model/dataset lineage
- Identification of components, parameters, triggers, and compute needs
- Constructing and testing of parameterized pipeline definition in SDK
- Organization and tracking experiments and pipeline runs
- Testing for target performance
- Decoupling components with Cloud Build
- Track and audit metadata
- Performing data validation
- Storing data and generated artifacts
Professional-Machine-Learning-Engineer dumps Sure Practice with 72 Questions: https://www.dumpsquestion.com/Professional-Machine-Learning-Engineer-exam-dumps-collection.html
Get New Professional-Machine-Learning-Engineer Certification – Valid Exam Dumps Questions: https://drive.google.com/open?id=14cgyCtflcKj2rjyG33ftKZNVgdBDZ28C